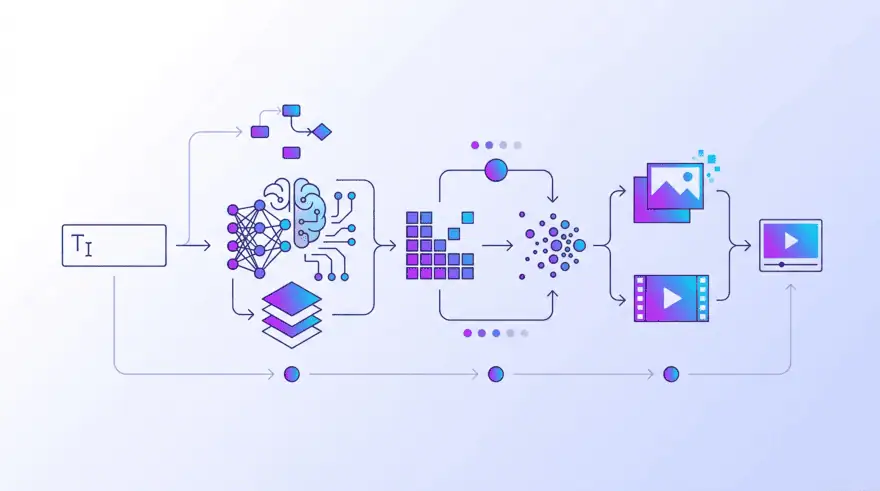
TL;DR: AI creates images and videos by learning patterns from billions of captioned examples, then turning random noise into a picture that matches your text prompt through a step-by-step “denoising” process called diffusion. Video works the same way, with an extra job: keeping every frame consistent over time. This guide explains exactly how that pipeline works, from the prompt you type to the pixels you get back, without the hype.
I typed “a golden retriever wearing sunglasses on a surfboard, cinematic light” into an AI image generator last week and had a usable, photo-real picture in about four seconds. No camera. No dog. No surfboard. Most people I show this to react the same way: that feels like magic, so how does it actually work?
It isn’t magic, and you don’t need a maths degree to understand it. Once you see what’s happening under the hood, the whole thing makes sense, and you’ll also understand why these tools fail in the exact ways they do (broken hands, garbled text, melting backgrounds). That understanding is the difference between fighting the tool and getting what you want out of it.
I’ve generated tens of thousands of images and a good amount of AI video over the past few years for real projects, real clients, and my own sites. I’m not a researcher who trains these models, I’m a practitioner who uses them daily and reads the papers so you don’t have to. In this guide I’ll walk through the full process of how AI generates images and how that extends to video, in plain language, with the real terminology so you can go deeper if you want.
By the end you’ll understand the training phase, diffusion, how a text prompt steers the picture, why video is so much harder than a still image, and the honest limits of what this technology can and can’t do in 2026. If you’d rather skip the theory and just start creating, my roundup of the best free AI image generators gives you tools to test these ideas in the next five minutes.
Key Takeaways
- AI doesn’t “draw” or copy. Modern AI image generators start from pure random noise and gradually clean it up into a picture that matches your prompt. This step-by-step cleanup is called diffusion, and it powers most tools you’ve heard of.
- The intelligence comes from training. Models learn by studying billions of image and text pairs, so they build a statistical sense of what words like “sunset,” “corgi,” or “Rembrandt lighting” tend to look like. They generate new images, they do not retrieve existing ones.
- Your prompt is a steering wheel, not a search query. A text encoder turns your words into numbers, and those numbers nudge the denoising process toward an image that fits the description.
- Video is images plus time. AI video models generate many frames at once and add a hard new constraint: consistency across frames, so the dog stays the same dog as it moves. This is why AI video is years behind AI images in reliability.
- The limits are predictable. Hands, on-image text, physics, and long clips break because of how these models work, not because they’re “not smart enough yet.” Knowing the mechanism tells you where to trust the output and where to check it.
The model isn’t recalling a picture it has seen. It’s predicting what a picture should look like, one small correction at a time.
How Does AI Actually Create Images?
AI creates an image by starting with a canvas of random visual noise and repeatedly refining it until the noise resolves into a coherent picture that matches your text prompt. It learned how to do this by training on hundreds of millions to billions of images paired with text descriptions, which taught it the statistical relationship between words and visual patterns.
That’s the whole idea in one paragraph. Everything else is detail.
Here’s the mental model I use. Imagine a sculptor staring at a rough block of marble. A beginner sees stone. A master sees the statue already inside it and just removes everything that isn’t the statue. An AI image generator does something close to that, except its “marble” is a grid of random pixels, and instead of chipping away stone, it removes random noise a little at a time until a picture emerges. Your prompt tells it which statue to find in the noise.
This matters because it corrects the single most common misconception I hear: that AI image generators search a giant database and stitch together bits of existing photos. They don’t. A trained model is a set of numbers (weights) that encode learned patterns. When you generate an image, the model produces brand new pixels that have never existed before. That distinction sits at the heart of both how the technology works and the copyright debate we’ll get to later in this guide.
Three things have to happen for any of this to work:
- Training: the model studies a massive dataset of images and their captions and learns the patterns that connect them.
- Conditioning: your text prompt gets converted into numbers the model can act on.
- Generation: the model turns noise into a finished image, guided by those numbers.
Let’s take them in order.
How Do AI Models Learn From Billions of Images?
AI image generation rests on machine learning: each AI model is built from neural networks, the brain-inspired math behind modern artificial intelligence. The model learns during a one-time training phase, where it’s shown enormous datasets of images paired with text captions. It repeatedly tries to predict visual patterns from text, checks how wrong it was, and adjusts its internal weights. After billions of these tiny corrections, it has built a statistical map linking language to visual features.
Think of training like a student flipping through billions of flashcards. One side has a picture, the other side has a caption like “a red bicycle leaning against a brick wall.” Over time the student stops memorising individual cards and starts internalising concepts: what “red” looks like, how “brick” differs from “wood,” what a bicycle’s geometry is. That generalisation is the entire point. A well-trained model can generate a red bicycle in a setting it never saw in training, because it learned the idea of each piece.
Where do AI image generators get their training images?
Most large models were trained on images scraped from the public web, organised into datasets with their alt text and surrounding captions. The best-known example is LAION-5B, an open dataset of about 5.85 billion image and text pairs that was used to train early versions of Stable Diffusion (LAION). Other models use a mix of licensed libraries, partner data, and proprietary collections.
This is exactly where the controversy lives. When Marcus, a freelance illustrator I know, found his portfolio had likely been swept into a web-scale training set without permission or payment, he was furious, and he had a point. Whether training on copyrighted work counts as fair use is being fought in court right now, including high-profile cases against Stability AI and Midjourney. It’s also why Adobe built Firefly on Adobe Stock, openly licensed, and public domain content, then marketed it as commercially safe. The training data a model used affects what you’re legally and ethically comfortable doing with its output.
What the model actually stores
A common worry is that the training images are hidden inside the model somewhere. They’re not, at least not as retrievable files. Stable Diffusion’s model file is a few gigabytes, yet it “learned” from billions of images that would take petabytes to store. The model can’t be a zip file of its training set. What it holds is a compressed set of statistical patterns, the same way your brain holds the concept of “dog” without storing every dog you’ve ever seen. The images generated from those patterns are fresh pixel arrangements, not files pulled from storage. (Edge cases exist where a model can regurgitate a near-copy of a heavily duplicated training image, which is a real research and legal concern, but it’s the exception, not the mechanism.)
Diffusion Models: How AI Turns Noise Into a Picture
Diffusion is the dominant method behind today’s AI image generators, including Stable Diffusion, DALL-E 3, Midjourney, and Google Imagen. A diffusion model works by learning to reverse a noising process: during training it watches clean images get destroyed into static, and it learns to undo that destruction one step at a time. To generate a new image, it starts from pure static and runs the cleanup in reverse.
The foundational paper here is Ho, Jain, and Abbeel’s 2020 work on denoising diffusion probabilistic models (arXiv), which kicked off the modern wave. Let me break the two halves down.
Forward diffusion: teaching the model what “broken” looks like
During training, the model takes a clean image and adds a small amount of random Gaussian noise. Then it adds a bit more. And more. After enough steps, the original image is indistinguishable from TV static. This forward process is deliberately simple and is not where the learning happens. It’s the answer key.
The clever bit: at each step, the system knows exactly how much noise it added. So it can hand the model a noisy image and ask, “what noise did I just add to this?” The model guesses, gets graded against the known answer, and updates. Repeat across billions of images and noise levels, and the model becomes an expert at one narrow skill: looking at a noisy image and predicting the noise.
Reverse diffusion: building an image from static
Generation runs that skill backwards. The model starts with a canvas of pure random noise, predicts the noise it thinks is “wrong,” and subtracts a portion of it. That leaves a slightly cleaner image. It looks at that, predicts again, subtracts again. After somewhere between roughly 20 and 50 steps in modern samplers, structured detail emerges from the static and you have a finished picture.
With each pass it continues to refine the image. Each step is a small, confident correction rather than one giant leap. That’s why diffusion produces such coherent results: it sneaks up on the image gradually instead of trying to nail it in a single shot. It’s also why generation takes a moment and why “more steps” can mean more detail (with diminishing returns).
Latent diffusion: the trick that made it fast and cheap
Running diffusion directly on full-resolution pixels is brutally expensive. A 1024 by 1024 image is over a million pixels, each refined dozens of times. The breakthrough that put image generation on your laptop was latent diffusion, introduced by Rombach and colleagues in 2022 (arXiv) and the basis of Stable Diffusion.
The idea: don’t diffuse in pixel space, diffuse in a compressed “latent” space. A separate network called a variational autoencoder (VAE) squeezes the image down to a much smaller numerical representation that keeps the meaningful structure and throws away redundant detail. All the slow denoising happens in that small space, and only at the very end does the VAE decode the result back into a full-resolution image. This cut the compute cost dramatically and is a big reason you can run these models without a data centre.
How Do Text Prompts Become Images?
Your text prompt becomes an image through conditioning. A text encoder converts your text description into a list of numbers (an embedding) that captures its meaning, and those numbers are injected into the denoising process at every step. Even a simple text prompt of a few words gives the model enough of a target to work toward. They act as a constant instruction, pulling the emerging image toward something that matches your description.
Without conditioning, a diffusion model would still turn noise into a perfectly plausible image, it just wouldn’t be your image. It might be a random face, a random landscape, anything it found in the noise. The prompt is what makes the output yours. Here’s how the words get in.
Turning words into numbers
Computers don’t understand “sunglasses.” They understand numbers. So the first step runs your prompt through a text encoder, a neural network trained to map language into a mathematical space where similar meanings sit close together. The most influential one is CLIP, released by OpenAI in 2021, which was trained on around 400 million image and text pairs to learn a shared space where a picture of a cat and the words “a cat” land in nearly the same spot (arXiv). Some models, like Imagen and Stable Diffusion 3, also use large language-model text encoders such as T5 for stronger prompt understanding.
The output is an embedding: a long list of numbers representing the meaning of your prompt. “A golden retriever in sunglasses” produces a different set of numbers than “a husky in a hat,” and those differences are what steer the picture.
Steering the denoiser with cross-attention
At each denoising step, the model doesn’t just predict noise blindly. It consults your prompt embedding through a mechanism called cross-attention, which lets different regions of the image “pay attention” to different words. The patch of canvas that’s becoming a face attends strongly to “golden retriever,” the region up top attends to “sunglasses,” and so on. Attention is the same core idea behind modern language models, introduced in the 2017 “Attention Is All You Need” paper (arXiv).
There’s also a dial called classifier-free guidance. In simple terms, the model generates one prediction that follows your prompt and one that ignores it, then exaggerates the difference. Crank the guidance scale up and the image obeys your prompt more strictly but can look forced or oversaturated. Turn it down and you get more creative, looser results. Most tools expose this as a “prompt strength” or “guidance” slider.
Why the same prompt gives different images
The starting noise is random, and that starting point is set by a number called the seed. Same model, same prompt, same seed, same settings will reproduce the exact same image every time. Change the seed and you get a different roll of the dice from the same description. This is why “regenerate” gives you variations: a new seed lets the model generate image after image from the same words, each one different. Sharing a seed lets someone recreate your exact result. When Priya, a designer on a small team I advised, learned to lock her seed and change only one word at a time, her hit rate on usable images roughly doubled, because she was finally running controlled experiments instead of gambling.
GANs, VAEs, and Other Ways AI Generates Images
Diffusion dominates today, but it isn’t the only approach, and the alternatives explain a lot of AI image history. The three other families worth knowing are generative adversarial networks (GANs), autoregressive transformer models, and variational autoencoders. Each generates new images, but the method and trade-offs differ.
Generative adversarial networks were the headline technology before diffusion. Proposed by Ian Goodfellow and colleagues in 2014 (arXiv), a GAN pits two networks against each other: a generator that creates fake images and a discriminator that tries to spot fakes. They train in competition until the generator’s output is convincing enough to fool the critic. StyleGAN’s photorealistic faces (the “this person does not exist” demos) came from this approach. GANs are fast at generation because they produce an image in a single pass, but they’re notoriously unstable to train and hard to control with detailed text prompts, which is why diffusion overtook them for general text-to-image work.
Autoregressive models treat an image like a sentence and predict it piece by piece. The original DALL-E from 2021 worked this way, generating image “tokens” one after another like a language model writing words. This approach faded for a while, then came roaring back: GPT-4o’s native image generation, released in 2025, is autoregressive and produces noticeably better text-in-images and instruction-following than pure diffusion, at the cost of speed.
Variational autoencoders rarely generate finished images alone anymore, but as you saw, the VAE is the workhorse compressor inside latent diffusion. So it didn’t lose, it got absorbed into the winning stack.
| Method | How it generates | Strengths | Weaknesses |
|---|---|---|---|
| Diffusion | Denoises random static step by step | High quality, controllable, stable training | Slower (many steps), heavy compute |
| GAN | Generator vs discriminator, one pass | Very fast generation, sharp faces | Unstable training, weak text control |
| Autoregressive | Predicts image tokens in sequence | Strong prompt and text rendering | Slow, expensive at high resolution |
| VAE | Encodes and decodes via latent space | Efficient compression | Blurry on its own; used as a component |
The practical takeaway: when you read that a tool is “diffusion-based” or “autoregressive,” you now know roughly what trade-offs you’re getting. For a hands-on look at how these differences show up in real output, I compare actual results across tools in my best AI tools guide.
From U-Net to Transformers: Why the Newest Models Changed Engines
For years, the denoising network at the centre of diffusion models was a U-Net, a convolutional architecture good at image-shaped data. The newest generation of models (Stable Diffusion 3, Flux, and OpenAI’s Sora) swapped it for a diffusion transformer, or DiT, introduced by Peebles and Xie in 2023 (arXiv).
Why bother? Because transformers scale. The lesson from large language models is that transformer performance keeps improving predictably as you add data and compute, and DiT brings that same scaling behaviour to image and video generation. Instead of processing the image as a grid through convolutions, a DiT chops the latent representation into patches and treats them like tokens, applying the same attention machinery that powers ChatGPT and Claude. This is the architectural reason the 2025 and 2026 models render cleaner text, follow complex prompts better, and, crucially, made high-quality AI video possible.
That last point is the bridge to the harder half of this topic.
How Does AI Generate Video, Not Just Images?
AI generates video by extending image diffusion across time: instead of producing one image, the model produces a sequence of frames together, while enforcing temporal consistency so objects, lighting, and motion stay coherent from frame to frame. Modern systems like OpenAI’s Sora treat video as a 3D block of data (width, height, and time) and denoise patches of that block all at once.
If a single image is a hard problem, video is that problem multiplied and then handed a brand new one. Let me explain why.
Why video is exponentially harder than a still image
A five-second clip at 24 frames per second is 120 individual images. Generating 120 plausible frames isn’t enough, because each frame has to agree with the others. The coffee cup in frame 1 must be the same cup, same colour, same position-plus-motion, in frame 120. Get that wrong and you get the classic AI video failures: a face that subtly morphs, a background that shifts, objects that pop in and out of existence. Humans are exquisitely sensitive to this kind of flicker, so the bar for “believable” is brutally high.
On top of consistency, video models have to learn an implicit sense of physics: how cloth falls, how water moves, how a person’s gait works. They learn this only by watching huge amounts of video, and they get it approximately right, which is why AI video still struggles with precise cause and effect.
Spacetime patches: how Sora and similar models work
OpenAI’s approach with Sora, described in its technical report “Video generation models as world simulators” (OpenAI), is to compress video into a lower-dimensional latent space and then cut it into spacetime patches, small chunks that span both a region of the frame and a slice of time. The diffusion transformer denoises all these patches together. Because the model sees space and time at once, it can keep motion and appearance consistent rather than generating each frame in isolation. It’s latent diffusion plus the transformer architecture, applied to a video-shaped block instead of a flat image.
Other leading 2026 video models use related strategies. Google’s Veo 3 can generate clips with natively synchronised audio, dialogue, sound effects, and ambience generated together with the picture (Google DeepMind). Runway, Kling, and Luma’s Dream Machine each have their own takes, but the core pattern, denoising a latent video representation with a transformer while conditioning on text or a starting image, is now industry-standard.
Adding sound and starting from an image
Two features changed AI video from a novelty into something usable. First, image-to-video: you give the model a still frame and a motion prompt, and it animates from that anchor, which gives you far more control than text alone. Second, native audio: rather than bolting on sound afterward, models like Veo 3 generate audio and video jointly so lip movement and sound effects actually line up. Both are conditioning tricks, the same principle as text prompts, just with an image or an audio target added to the steering signal.
The honest limits of AI video in 2026
Here’s where I’ll be blunt, because the marketing won’t be. AI video in 2026 is genuinely impressive and still genuinely limited:
- Length: most tools produce clips in the 5 to 60 second range. True long-form, story-consistent video is not a solved problem.
- Character consistency: keeping the same character across multiple shots remains fiddly and often needs reference images or extra tooling.
- Physics and cause-effect: complex interactions (a glass shattering correctly, precise hand-object contact) still break.
- Control: getting an exact camera move or precise edit is harder than describing a vibe.
- Cost and time: high-quality video generation is compute-heavy, so it’s slower and pricier than images.
If you want the current state of which tools handle these limits best, I keep an honest, tested view in my best AI tools roundup rather than repeating vendor claims here.
What Can AI Image and Video Generators Actually Make?
AI generators can produce a wide range of visual content from text or image prompts: photorealistic images, illustrations and digital art, product mockups, logos and icons, marketing visuals, concept art, stock-style photography, short video clips, animations, and edits to existing media such as background removal or style transfer. The range expands every few months.
In day-to-day work, the realistic use cases I see actually paying off are marketing and social graphics, blog and ad imagery, product visualisation and mockups, storyboarding and concept art, and short video for ads and social. The technology is strong at “give me a good-enough visual fast and cheap” and weaker at “give me this exact thing with pixel precision,” which maps directly onto the mechanism: it’s a probabilistic system that predicts likely images, not a deterministic one that executes exact instructions.
A quick reality check on quality: the gap between a mediocre and a great result is mostly your prompt and your settings, not the tool. Understanding diffusion and conditioning is what lets you write prompts that work with the model instead of against it.
What AI Image and Video Generation Can’t Do Well Yet
Knowing the mechanism tells you exactly where these tools fail, and the failures are consistent. AI image generators still struggle with legible text inside images (improving fast with autoregressive and DiT models, but not solved), hands and fingers (complex, variable geometry the model often averages wrong), precise counts (“exactly five apples” frequently isn’t five), consistent characters across multiple images, and factual or physical accuracy.
None of these are random. Text and counting break because diffusion models optimise for overall plausibility, not symbolic precision, so “texty-looking shapes” satisfy the objective. Hands break because they appear in thousands of poses and the model learns an averaged, often mangled, prior. The fixes are the same everywhere: better architectures (transformers and autoregressive models are closing the text gap), bigger and cleaner training data, and on your end, clearer prompts plus a quick human check before anything ships.
There’s also the issue of hallucination and bias. A model reflects its training data, so it can reproduce stereotypes, miss underrepresented groups, or confidently invent details. That’s not a bug you can prompt away. It’s a property of statistical generation, and it’s why human review matters for anything public-facing.
Are AI-Generated Images and Videos Copyrighted? Can You Use Them Commercially?
In the United States, the Copyright Office has stated that a purely AI-generated image, created from a text prompt with no meaningful human authorship, is not eligible for copyright protection (U.S. Copyright Office). Human-authored elements and substantial creative editing can be protected, but the raw AI output generally can’t be owned the way a photograph you take can. Commercial use is a separate question from ownership, and most major tools do let you use generated images commercially under their terms.
So can you put AI images on your website, ads, and products? In most cases yes, but read the fine print, because two different risks are in play.
Ownership risk: if you can’t copyright the output, a competitor could in theory use the same or a similar image and you’d have limited recourse. For a lot of marketing work this doesn’t matter. For a brand logo you want to defend, it matters a lot.
Training-data risk: several lawsuits (including artists versus Stability AI and Midjourney, and Getty Images versus Stability AI) are testing whether training on copyrighted work, and generating outputs that resemble it, infringes. The outcomes will shape what’s safe. This is why Adobe Firefly trained on licensed and public-domain content and offers commercial indemnification: it’s selling legal peace of mind, not just pixels.
My practical rule: for general marketing visuals, AI output is fine and a genuine money-saver. For anything you need to legally own or that imitates a living artist’s style, slow down, add real human authorship, and consider a commercially-safe model. If saving money on tooling is the goal, that’s a recurring theme on ZPlatform, where I track which AI tools and deals are actually worth it.
How to Get Better Results Now That You Understand the Process
Understanding the pipeline pays off the moment you write your next prompt. A few habits that flow directly from the mechanism:
- Describe, don’t command. The model matches patterns from captions, so write the way a good caption reads: subject, setting, style, lighting, mood. “Command” phrasing like “make sure there are exactly three people” fights the model’s strengths.
- Lock your seed to iterate. Fix the seed and change one element at a time so you can see what each word does. This turns guessing into controlled testing.
- Tune guidance. If results feel generic, raise prompt strength. If they feel stiff or fried, lower it.
- Use image-to-image and references when you need control over composition or a consistent character, instead of relying on text alone.
- Always do a human pass on hands, text, counts, and faces before anything goes public.
These five habits will do more for your output than switching tools. The model is the same engine for everyone; the people who get great results are the ones who understand what it’s doing.
Conclusion: It’s Prediction, Not Magic
Strip away the wonder and AI image and video generation comes down to one elegant trick repeated at massive scale: learn the patterns connecting language and pixels from billions of examples, then turn random noise into a picture that fits your words, one small correction at a time. Video adds the dimension of time and the hard requirement of consistency, which is why it trails images in reliability. Everything else, diffusion, latent space, text encoders, transformers, GANs, is detail on that core idea.
Here’s the insight I’d leave you with. These tools aren’t getting better at “creativity” in a human sense. They’re getting better at prediction, through better architectures (the shift to transformers) and more and cleaner data. That’s also why their weaknesses are so predictable: anywhere the task needs exactness rather than plausibility, the seams show. Treat AI as a fast, brilliant intern who needs checking, not an oracle, and you’ll get the value without the embarrassing mistakes.
Your concrete next step: pick one tool, write a single descriptive prompt, then regenerate it three times with the same seed and one changed word each time. Watch what each change does. You’ll learn more in ten minutes of deliberate testing than in an hour of reading. When you’re ready to choose a tool, my tested, no-hype guide to the best free AI image generators will point you to one that fits your needs and budget.
Frequently Asked Questions
How does AI generate images from text?
AI converts your text prompt into a numerical embedding using a text encoder like CLIP, then uses that embedding to steer a diffusion model that turns random noise into a matching image over roughly 20 to 50 refinement steps. The words act as a constant instruction guiding each step toward a picture that fits your description.
How does AI art work?
AI art works through generative models, most commonly diffusion models, that have learned patterns from billions of image and caption pairs. When you prompt them, they generate brand-new pixels that statistically match your words, rather than retrieving or collaging existing artwork. The output is original to that generation, though the model’s “taste” comes from its training data.
Where do AI image generators get their images?
Their training images come from large datasets, often scraped from the public web with captions and alt text, such as the open LAION-5B set of about 5.85 billion image-text pairs. Some models, like Adobe Firefly, instead train on licensed and public-domain content. The model learns patterns from these images but doesn’t store or retrieve them when generating.
Can I use AI-generated images commercially?
In most cases yes, under the terms of the tool you used, and many platforms explicitly allow commercial use. The catch is ownership: in the United States, purely AI-generated images generally can’t be copyrighted, so you may not be able to stop others from using a similar image. For work you need to legally own, add substantial human authorship or use a commercially-indemnified model.
What is the difference between diffusion models and GANs?
Diffusion models generate images by gradually denoising random static over many steps, which gives high quality and strong prompt control but is slower. GANs (generative adversarial networks) use a generator and a discriminator competing in a single pass, which is fast but harder to train and weaker at following detailed text prompts. Diffusion has largely replaced GANs for text-to-image generation.
How does AI video generation work?
AI video models extend image diffusion across time, generating many frames together while enforcing temporal consistency so objects and motion stay coherent. Systems like OpenAI’s Sora compress video into a latent space, cut it into spacetime patches, and denoise them with a diffusion transformer, conditioned on your text or a starting image. Some models, like Google’s Veo 3, also generate synchronised audio.
Why do AI images get hands and text wrong?
Because diffusion models optimise for overall plausibility, not symbolic precision. Hands appear in countless poses, so the model learns an averaged prior that often produces extra or misshapen fingers. Text breaks because “text-shaped” marks satisfy the model’s objective without being readable. Newer transformer and autoregressive models are closing the text gap fast.
How long can AI-generated videos be?
As of 2026, most tools produce clips in the 5 to 60 second range, with quality and consistency dropping as length increases. Generating long, story-consistent video with stable characters across multiple scenes is still an unsolved problem, which is why current AI video shines for short ads, social clips, and b-roll rather than full productions.
Related Posts
AI adoption statistics for 2026: 78% of companies now use AI, the market hits $37.89B, plus country, industry, and ROI d...

What It Does ZPlatform’s AI Prompt Manager is a Chrome extension that helps you save, organize, and reuse AI prompts for...

AI product discovery jumped 4,700% in a year. This AI shopping assistant guide ranks the best tools, exact prompts, and ...
I evaluated 30+ AI SEO agencies in the US, UK, and worldwide. Here’s who’s actually delivering on GEO, LLM visibility, a...
The 125 best digital marketing agencies in India, ranked by verified Google reviews. Compare ratings, services, cities, ...
37 best places to launch your product, SaaS, or AI tool in 2026, ranked by Ahrefs Domain Rating with honest pros, cons, ...