
Short answer: A token in AI is a small chunk of text, a whole word, part of a word, a character, or a piece of punctuation, that an AI model reads and generates. Large language models like ChatGPT, Claude, and Gemini do not actually see “words”; they break text into tokens first, then process those. As a rule of thumb in English, 1 token is about 4 characters, or roughly three-quarters of a word, so 1,000 tokens is around 750 words. Tokens matter because they decide how much text a model can handle at once (its context window) and how much an AI API costs, since you pay per token.
This guide explains tokens in plain English, with real examples, then shows how tokenization works, why tokens drive AI cost and limits, and how tokens behave inside large language models. Jump to how tokenization works, the tokens-vs-words rule, or why tokens matter.
Key takeaways
- A token is the basic unit of text an AI model processes, often a word or part of a word, not always a full word.
- 1 token ≈ 4 characters ≈ 0.75 words in English; ~1,000 tokens ≈ 750 words (OpenAI’s rule of thumb).
- Models read and write in tokens, then convert back to text, this is called tokenization.
- Tokens decide two practical things: the context window (how much text fits at once) and cost (AI APIs charge per token, input and output).
- Token counts vary by language and model; non-English text and code often use more tokens.
What is a token in AI?
A token in AI is the smallest piece of text a model works with. When you type a prompt, the AI does not process it letter by letter or as neat dictionary words. Instead, it splits your text into tokens, units that can be a full word (“cat”), part of a word (“token” + “ization”), a single character, a space, or punctuation, and then works with those. So, what is token in AI in one sentence? It is the smallest unit of text an AI system reads. AI models process text as tokens, not words, using a single token for a short common word and several tokens for a long one.
So what is an AI token, exactly? It is a numerical representation of a text chunk. Each token maps to an ID number in the model’s vocabulary, and the model does all its math on those numbers. When it responds, it generates tokens one at a time and converts them back into readable text. You never see the tokens; they are the hidden currency the model actually thinks in.
This is true across modern AI: ChatGPT, Claude, Gemini, and other large language models all operate on tokens, not words.
How tokenization works
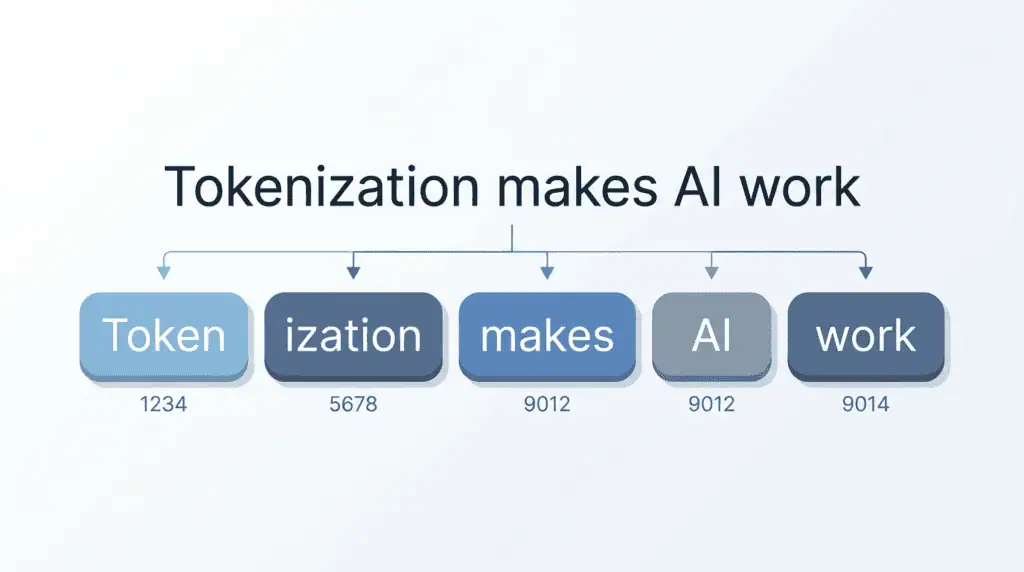
The process of splitting text into tokens is called tokenization, and most modern models use an approach called subword tokenization (commonly Byte Pair Encoding, or BPE; see NVIDIA’s explainer on AI tokens). Instead of giving every possible word its own token, which would need a gigantic vocabulary, the model breaks rarer or longer words into smaller, reusable pieces.
Here is what that looks like in practice:
- “cat” → 1 token (common short word).
- “tokenization” → often 2 tokens, like `token` + `ization`.
- “ChatGPT” → may split into `Chat` + `GPT` (2 tokens).
- A space or punctuation mark → frequently its own token (the space before a word usually attaches to it).
This is why token counts feel unpredictable: common words are single tokens, while unusual words, names, code, or non-English characters get chopped into several. The model learned this vocabulary from huge amounts of text so it can represent almost anything efficiently.
Tokens vs words: the 4-character rule

The single most useful thing to remember: one token does not equal one word. According to OpenAI’s own guidance, a good rule of thumb for English is that one token is approximately four characters, or about 75% of a word. That gives you handy conversions:
- 1 token ≈ 4 characters ≈ ¾ of a word
- 100 tokens ≈ 75 words (about a paragraph)
- 1,000 tokens ≈ 750 words
- 1 page of text (~500 words) ≈ ~660 tokens
These are approximations, not exact math. Short, common words may be one token; long or rare words take more. Numbers, emojis, code, and languages other than English usually consume more tokens per word, which matters for both cost and limits.
Why tokens matter (3 real reasons)
Tokens are not just trivia, they directly affect how you use AI.
1. Context window (how much the AI can handle at once)
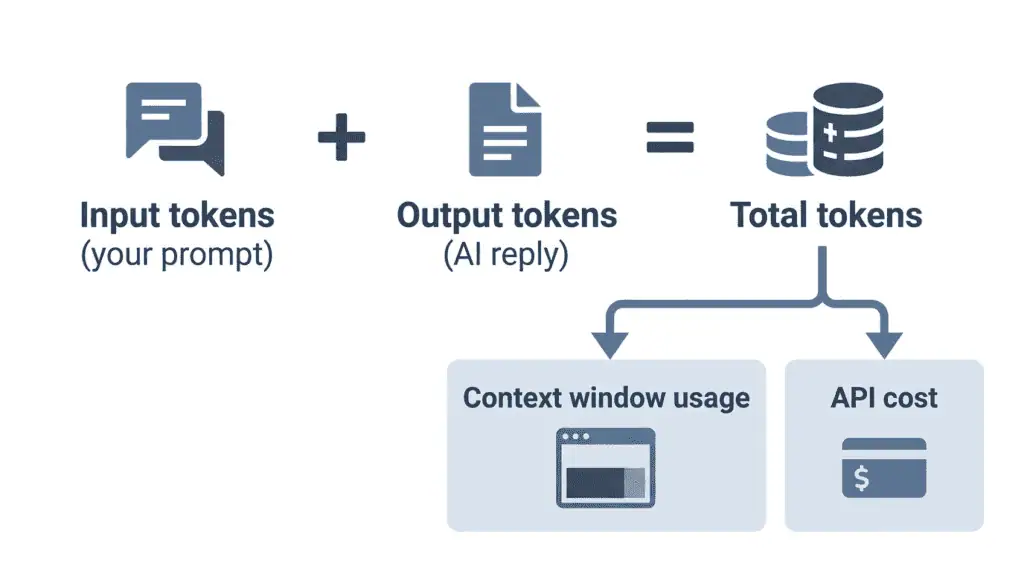
Every model has a context window, the maximum number of tokens it can consider in a single conversation, measured in tokens, not words. If a model has a 128,000-token context window, that is roughly 96,000 words of combined input and output. Go over the limit and the model truncates or forgets the earliest text. Understanding tokens is how you reason about “how much can I paste into this prompt?”
2. Cost (you pay per token)
AI APIs from OpenAI, Anthropic, and Google are priced per token, usually with separate rates for input and output tokens, that is, your prompt versus the model’s response. Output tokens often cost more. So a wordy prompt and a long answer both cost more, and counting tokens is how developers estimate and control their AI bills. This is the number-one reason engineers care about tokenization.
3. Performance and quality
Because models predict the next token based on previous tokens, token boundaries affect behavior. Awkward tokenization (common with code, rare words, or other languages) can subtly hurt quality and waste context. Efficient prompts use fewer tokens to say the same thing.
What is a token in AI large language models?
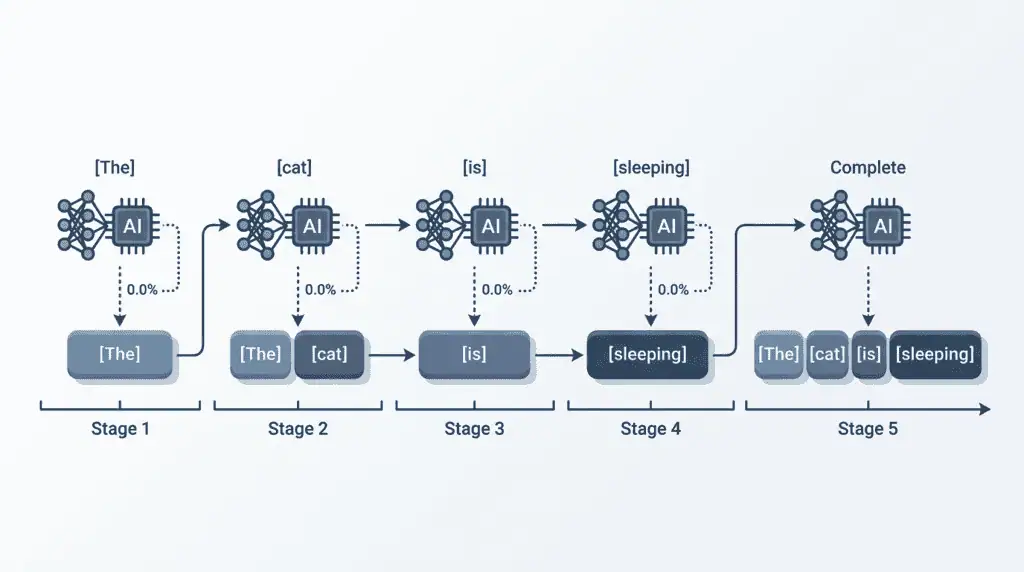
In large language models (LLMs), a token is the fundamental unit the model is trained and run on. During training, the model learns to predict the next token in a sequence across trillions of tokens of text. During use, it reads your prompt as tokens and generates its answer token by token, each new token chosen based on all the tokens before it. A large language model may even assign a different token to the same word when its capitalization or spacing changes.
That is why you sometimes see ChatGPT “type” its answer progressively, it is producing one token at a time. The model’s size and capability are often described in tokens too (for example, “trained on 15 trillion tokens”), and its limits (context window, output length) are all measured in tokens. For LLMs, tokens are not a detail; they are the substance the model is made of.
What is a token in AI language processing (NLP)?
In natural language processing (NLP), tokenization is one of the first and most important steps in the pipeline. Before any analysis, raw text is broken into tokens so a computer can work with it. Classic NLP often tokenized by words or sentences; modern AI uses subword tokens because they handle unknown words, typos, and many languages far better. So “a token in AI language processing” is simply the unit of text produced by that splitting step, the building block everything else is built on.
How to count tokens
You do not have to guess. Free tools show exactly how your text tokenizes:
- OpenAI’s Tokenizer (and the `tiktoken` library) let you paste text and see the token count and the split.
- Most AI provider dashboards display token usage per request.
- A quick mental estimate: characters ÷ 4, or words × 1.33.
If you build with AI, counting tokens is how you stay inside context limits and predict cost. For more on working with these tools, see our roundup of the best free AI tools.
Token Limits Compared: Every Major AI Model in 2026
Context window size - how many tokens an AI model can process in one conversation - varies massively across models. Here is the current state.
| AI Model | Context Window (Tokens) | Approx. Word Equivalent | What Fits |
|---|---|---|---|
| Claude 3.5 Sonnet / Claude 4 | 200,000 | ~150,000 words | A full novel or 500-page report |
| Gemini 1.5 Pro | 1,000,000 | ~750,000 words | Multiple books or a full codebase |
| Gemini 1.5 Flash | 1,000,000 | ~750,000 words | Same as Pro, cheaper and faster |
| GPT-4o | 128,000 | ~96,000 words | A long novel chapter or large document |
| GPT-4o mini | 128,000 | ~96,000 words | Same window, lower cost model |
| o1 / o3 | 200,000 | ~150,000 words | Full documents with reasoning |
| Llama 3.1 (Meta) | 128,000 | ~96,000 words | Large documents, open source |
| Mistral Large | 128,000 | ~96,000 words | Enterprise documents |
| Perplexity (Sonar) | 127,000 | ~95,000 words | Long research sessions |
| DeepSeek R1 | 128,000 | ~96,000 words | Complex reasoning tasks |
Token Costs Compared: What Does It Cost Per 1 Million Tokens?
Token pricing varies by 100x between models. For developers and businesses using AI via API, this table determines your monthly bill.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For |
|---|---|---|---|
| GPT-4o mini | $0.15 | $0.60 | High-volume, cost-sensitive tasks |
| Gemini 1.5 Flash | $0.075 | $0.30 | Cheapest capable model |
| Claude Haiku 3.5 | $0.80 | $4.00 | Fast, cheap Claude-family tasks |
| GPT-4o | $2.50 | $10.00 | Production quality at mid cost |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Best value in Claude 4 family |
| Gemini 1.5 Pro | $3.50 | $10.50 | Long context at reasonable cost |
| Claude Opus 4 | $15.00 | $75.00 | Most capable Claude, complex tasks |
| o3 (OpenAI) | $10.00 | $40.00 | Complex reasoning tasks |
Key insight: The cheapest model (Gemini Flash at $0.075/1M input tokens) costs 200x less than the most expensive (Claude Opus at $15/1M). For applications processing millions of tokens monthly, model selection is the most important cost lever.
Frequently asked questions
Is a token the same as a word? No. A token is often part of a word. On average in English, one token is about 4 characters or three-quarters of a word, so 1,000 tokens is roughly 750 words.
How many tokens are in a word? On average, about 1.33 tokens per English word. Short common words are 1 token; long or rare words can be several.
Why do AI tools charge per token? Because tokens are the actual unit of computation. Processing more tokens uses more compute, so APIs bill per input and output token, output usually costs more than input.
What is a token limit or context window? It is the maximum number of tokens a model can handle in one go, including your prompt and its reply. Exceeding it causes truncation or forgotten context.
Do other languages use more tokens? Yes. Non-English text, code, numbers, and emojis often tokenize into more tokens per word than plain English, which raises cost and uses context faster.
What is an AI token in crypto, is it the same? No, unrelated. In AI, a token is a chunk of text a model processes. In crypto, a token is a digital asset. This guide is about AI/LLM tokens.
The bottom line
Tokens are the hidden unit behind every AI text model. Once you know that AI reads and writes in tokens, not words, two practical things click into place: why models have context limits, and why AI usage is billed the way it is. Keep the rule of thumb handy, 1 token ≈ 4 characters ≈ ¾ of a word, and you can estimate cost and limits on the fly.
Next time you write a prompt, remember the model sees tokens, so being concise genuinely saves tokens, money, and context. To go deeper on the tools that put tokens to work, explore our guides to the best AI tools and how professionals use them.
Related Posts
AI adoption statistics for 2026: 78% of companies now use AI, the market hits $37.89B, plus country, industry, and ROI d...

What It Does ZPlatform’s AI Prompt Manager is a Chrome extension that helps you save, organize, and reuse AI prompts for...

AI product discovery jumped 4,700% in a year. This AI shopping assistant guide ranks the best tools, exact prompts, and ...
I evaluated 30+ AI SEO agencies in the US, UK, and worldwide. Here’s who’s actually delivering on GEO, LLM visibility, a...
The 125 best digital marketing agencies in India, ranked by verified Google reviews. Compare ratings, services, cities, ...
37 best places to launch your product, SaaS, or AI tool in 2026, ranked by Ahrefs Domain Rating with honest pros, cons, ...